当大多数人谈论互联网搜索引擎时,他们实际上指的是万维网搜索引擎。在万维网成为互联网最显眼的部分之前,就已经有搜索引擎来帮助人们在网上查找信息了。“gopher”和“Archie”等程序维护着连接到互联网的服务器上存储文件的索引,大大减少了查找程序和文档所需的时间。在20世纪80年代末,从互联网获取重要价值意味着知道如何使用gopher、Archie、Veronica等等。
如今,大多数互联网用户将搜索范围限制在网页上,因此本文将仅限于专注于网页内容的搜索引擎。
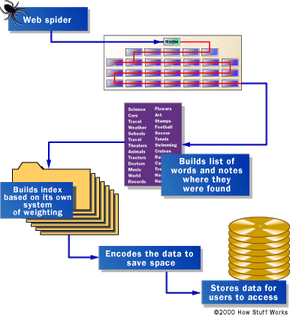
在搜索引擎告诉你文件或文档在哪里之前,它必须先找到这些文件或文档。为了在数亿个现有网页中查找信息,搜索引擎会使用特殊的软件机器人,称为蜘蛛,来构建网站上找到的词汇列表。当蜘蛛构建其列表时,这个过程被称为网页抓取。(将互联网的一部分称为万维网有一些缺点——工具命名中大量以蜘蛛为中心的就是其中之一。)为了构建和维护一个有用的词汇列表,搜索引擎的蜘蛛必须查看大量的页面。
任何蜘蛛是如何开始其在网络上的爬行之旅的呢?通常的起点是常用服务器和非常热门页面的列表。蜘蛛将从一个热门站点开始,索引其页面上的词汇并跟踪站点内找到的每个链接。通过这种方式,蜘蛛系统迅速开始遍历,扩散到网络上使用最广泛的部分。
Google最初是一个学术搜索引擎。在描述该系统如何构建的论文中,谢尔盖·布林 (Sergey Brin) 和拉里·佩奇 (Lawrence Page) 举了一个例子,说明他们的蜘蛛工作速度有多快。他们最初的系统设计为使用多个蜘蛛,通常一次使用三个。每个蜘蛛可以同时保持约300个网页连接。在其峰值性能下,使用四个蜘蛛,他们的系统每秒可以抓取超过100个页面,每秒生成约600千字节的数据。
保持一切快速运行意味着需要建立一个系统来向蜘蛛提供必要的信息。早期的Google系统有一个专门的服务器来向蜘蛛提供URL。Google没有依赖互联网服务提供商的域名服务器(DNS)来将服务器名称转换为地址,而是拥有自己的DNS,以便将延迟降至最低。
当Google蜘蛛查看HTML页面时,它会记录两件事:
出现在标题、副标题、元标签以及其他相对重要位置的词汇在随后的用户搜索中会得到特殊考虑。Google蜘蛛旨在索引页面上的每个重要词汇,省略冠词“a”、“an”和“the”。其他蜘蛛则采用不同的方法。
这些不同的方法通常旨在使蜘蛛运行更快、让用户搜索更高效,或两者兼而有之。例如,一些蜘蛛会跟踪标题、副标题和链接中的词汇,以及页面上100个最常用的词和前20行文本中的每个词。据称Lycos就是用这种方法抓取网页的。
其他系统,例如AltaVista,则走向另一个方向,索引页面上的每一个词,包括“a”、“an”、“the”以及其他“不重要”的词。这种方法对完整性的追求与其他系统对网页未见部分(元标签)的关注相匹配。 在下一页了解更多关于元标签的信息。